Motivation
在介绍命令模式的原理之前,我们先来一起考虑两个编程中经常遇到的现象。
实现一个功能
回想我们刚开始编程的时候,我们为了实现一个函数,于是根据这个函数开始设计它的输入输出,输入在写代码时我们一个一个敲入了函数接口中形成一堆参数,输出则放在函数的返回值中。
对于一些输入比较少的函数,可能就一个String,多的外加几个int值(例如string中字串的始末位置),这个时候函数的声明可能有点臃肿,但也还行。对于一个简单的函数,几十行代码就解决了,这种编程行为确实没啥问题,大伙都不会在意。
但随着需求越来越负载,这个函数承载的功能越来越多,于是几十行的代码可能会增长到百十行甚至更多。这时候大家为了代码的可读性,都会开始进行流程划分,一些逻辑内聚性强的代码就会封装到一个子函数中,原本的主函数只负责调用子函数,表征整体的大流程。那么这个时候就会发现,主函数的一些参数可能全部或者大部分都要向一个或多个子函数传递,于是就会发现我们的代码里,那几个参数被复制粘贴了若干遍,看起来十分臃肿/冗余。除了流程的复杂化,很可能函数的参数也要扩展,新增几个新的控制参数、布尔值,这都是很常见的现象。
这时候,相信很多同学为了少打几个变量、少复制几次,就会开始考虑开全局变量,这样一下子函数接口就会精简不少,所有要用的参数直接走全局空间里取就完事了,代码感觉清爽不少。另外一波同学可能会选择把这一批参数打个包,封装成一个类,函数接口改成接收单个对象,那么这样一下子接口是清爽很多,但是有的时候可能各个子函数里有得不停地把这一堆参数get出来,不过至少可以按需取用了,一些调用比较少的参数就可以直接get,调用比较多的参数就可以声明一个新的引用来减少get次数。
上面说的两种方式都一定程度上简化了代码,但是也都有一定的局限性。比如全局参数这种方式,如果是单线程任务,简单的跑跑OJ那种都没问题,但是实际场景中如果这个函数会同时被多个地方调用,显然一组全局参数是不足以支持多个线程任务同时使用的。第二种方式封装对象的方式我们已经分析了,会存在多次get这种情况。
那么再深入思考一下,这两种方式能否结合呢?怎么结合呢?我们回顾一下我们的思路,我们相当于是有一个executor,然后这个executor对外提供函数接口,我们将这个函数具体的实现代码都封装在了这个executor里。而对于外部的请求,我们考虑了将一堆参数封装成一个对象。那么我们可否任务,这一个对象就代表了这一次任务?我们已经通过这个对象告诉了这个executor执行这个任务需要的数据。那么再大胆一点,我们是否也可以直接告诉executor这个任务应该怎么做?也就是说我们把之前封装在executor里的函数实现直接封装到这个任务对象里,executor只需要调用这个对象提供的execute方法就可以完成任务,而且这样的封装还使得我们在编码时可以以全局变量的方式在任务类中取用任务参数,也省掉了各种get方法和局部变量的声明,不同任务之间的参数也不会互相影响执行。
那么经历过这样的思考与尝试,我们已经不知不觉触碰到了命令模式。
实现一组功能
上面我们回忆了平时我们在实现单个功能或任务时候的编程思路,但是在实际工作中,我们往往是要处理一组功能。而且有时候我们还是在团队协作,有可能按功能划分,每个人负责几个功能的实现(人人全栈);也有可能是按功能流程划分,比如某人负责功能的某一环节的处理(分层分工)。
那么在第二种分工中,就免不了相邻环节的同事要进行交流,商量一下互相协作与交互的接口,体现在代码上就是前一环节的组件要向后一环节的组件发起请求,不同任务可能有不同组件进行支撑。
我们假设A同学与B同学正在合作实现一组功能,他们采用分层分工,A同学负责上层的一些功能实现,然后需要向B同学发起请求或调用来完成后续的功能行为。那么这时候,可能B同学实现了一堆组件来支持不同的功能,那么A同学可能就需要知道每一个组件接口,比如是哪个类的哪个方法,然后编码时要持有引用、发起函数调用等。
这样的情况下,我们可以发现A同学与B同学是强耦合强依赖的,B同学的工作对与A同学来讲很大程度上不够透明。能否有一种方式,A同学可以不用关注B同学具体的实现,仅将任务传递给B即可。那么这时候命令模式又可以上场了。
在软件设计中,我们经常需要向某些对象发送请求,但是并不知道请求的接收者是谁,也不知道被请求的操作是哪个,我们只需在程序运行时指定具体的请求接收者即可,此时,可以使用命令模式来进行设计,使得请求发送者与请求接收者消除彼此之间的耦合,让对象间的调用关系更加灵活。命令模式可以对发送者和接收者完全解耦,发送者与接收者之间没有直接引用关系,发送请求的对象只需要知道如何发送请求,而不必道如何完成请求。这也是命令模式的模式动机之一。
命令模式原理
模式定义与结构
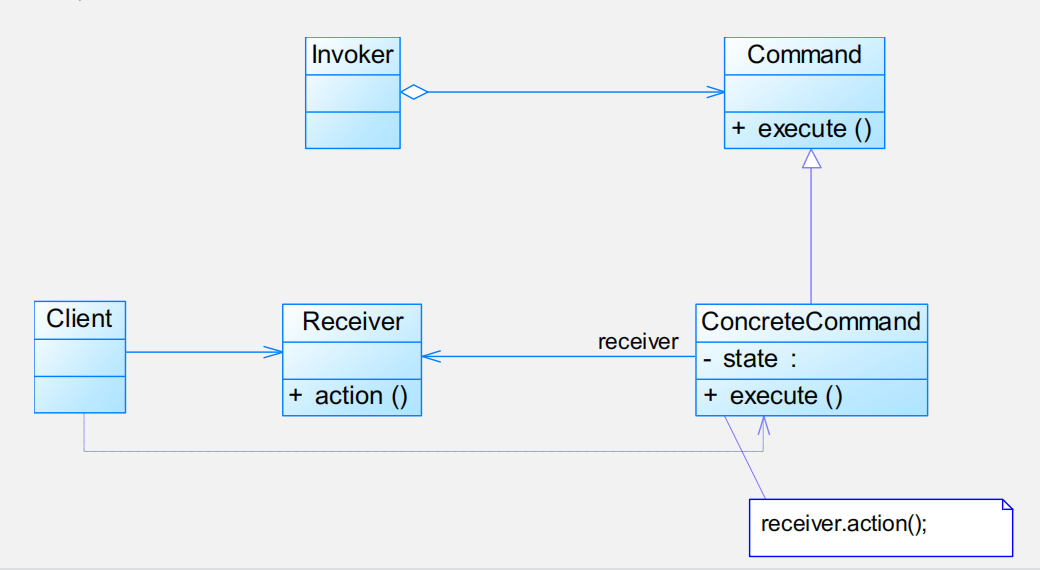
命令模式(Command Pattern):将一个请求封装为一个对象,从而使我们可用不同的请求对客户进行参数化;对请求排队或者记录请求日志,以及支持可撤销的操作。命 令模式是一种对象行为型模式,其别名为动作(Action)模式或事务(Transaction)模式。
命令模式包含如下角色:
- Command: 抽象命令类
- ConcreteCommand: 具体命令类
- Invoker: 调用者
- Receiver: 接收者
- Client: 客户类
模式分析
- 命令模式的本质是对命令进行封装,将发出命令的责任和执行命令的责任分割开。
- 每一个命令都是一个操作:请求的一方发出请求,要求 执行一个操作;接收的一方收到请求,并执行操作。
- 命令模式允许请求的一方和接收的一方独立开来,使得请求的一方不必知道接收请求的一方的接口,更不必知道请求是怎么被接收,以及操作是否被执行、何时被执行,以及是怎么被执行的。
- 命令模式使请求本身成为一个对象,这个对象和其他对象一样可以被存储和传递。
- 命令模式的关键在于引入了抽象命令接口,且发送者针对抽象命令接口编程,只有实现了抽象命令接口的具体命令才能与接收者相关联。
优点
- 降低系统的耦合度
- 新的命令可以很容易地加入到系统中
- 可以比较容易地设计一个命令队列和宏命令(组合命令)
- 可以方便地实现对请求地Undo和Redo
缺点
使用命令模式可能会导致某些系统有过多的具体命令类。因为针对每一个命令都需要设计一个具体命令类,因此某些系统可能需要大量具体命令类,这将影响命令模式的使用。
适用场景
- 系统需要将请求的调用者和接受者进行解耦,使得调用者和接收者不直接交互
- 系统需要在不同的时间指定请求,将请求排队和执行请求
- 系统需要将一组操作组合在一起,即支持宏命令
- 系统需要支持命令的Undo和Redo
Apache IoTDB中的命令模式
逻辑计划与物理计划
作为一款数据库,Apache IoTDB的架构遵循了经典的数据库架构,在SQL处理方面才用了基于逻辑计划与物理计划的设计。
熟悉数据库的同学都知道,我们通过SQL语句来使用数据库。SQL语句作为一门声明式的编程语言,只定义具体的任务,而不定义任务具体的执行过程。当我们提交一条SQL到数据库时,通过SQL语法解析,我们将得到该SQL描述的逻辑计划,该逻辑计划包含了SQL语句中定义的重要参数与算子。但是逻辑计划并不能明确具体的任务执行流程,于是数据库将逻辑计划中的逻辑概念与参数进行转化,转化为与实际物理存储相关的物理计划,然后数据库将基于物理计划按既定流程完成SQL的执行。
在Apache IoTDB中,SQL的解析通过Antlr4来实现,经过Antlr4解析所得的参数与算子将形成IoTDB的逻辑计划,在实际的代码中对应/server/src/main/java/org/apache/iotdb/db/qp/logical包下的一系列Operator类,每一个Operator类对应了一个具体的逻辑任务,例如InsertOperator对应了写入任务、QueryOperator对应了查询任务。
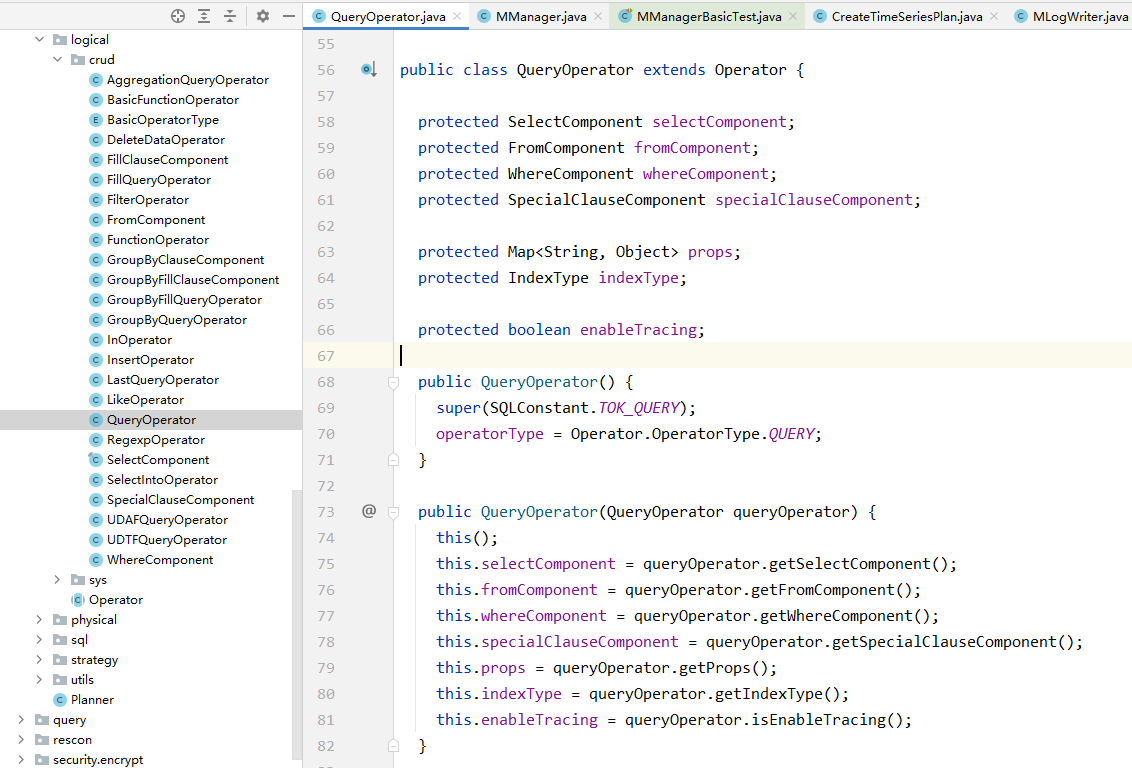
IoTDB中的逻辑计划Operator,每种Operator都封装了具体的生成物理计划的方法generatePhysicalPlan,该方法将由PhysicalGenerator调用,来实现从逻辑计划到物理计划的转化。物理计划对应了/server/src/main/java/org/apache/iotdb/db/qp/physical包下的一系列plan类,例如InsertPlan为写入任务的物理计划、RawDataQueryPlan为原始查询任务的物理计划。
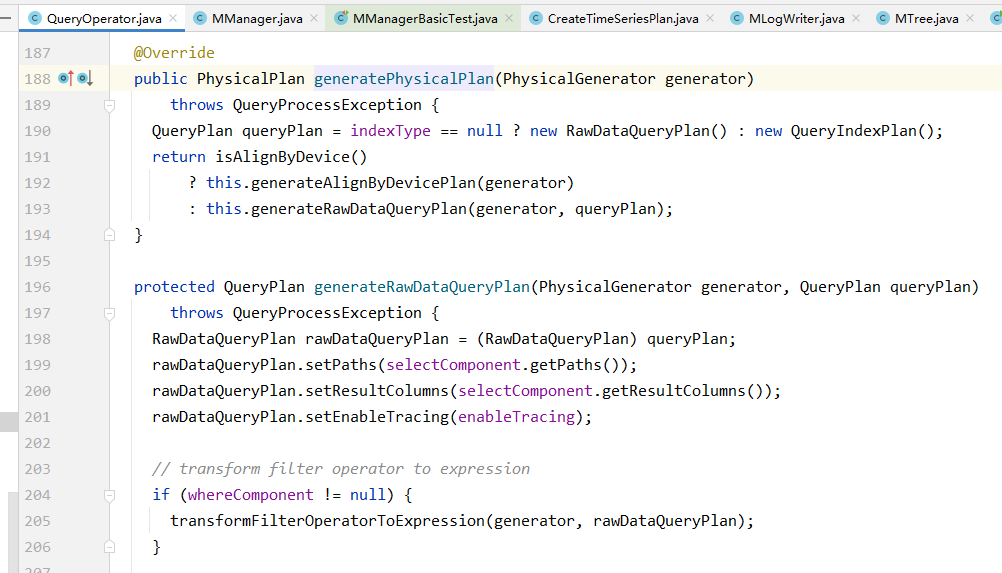
在IoTDB的物理计划生成过程中,一个典型的步骤就是针对SQL中输入的路径采取去*操作。IoTDB采用树形数据模型,树的每一个叶子节点代表一条时间序列,IoTDB提供通配符功能来帮助用户同时选中多条序列。假设元数据树上有root.sg.d1.s和root.sg.d2.s两条序列,那么用户可以使用root.sg.*.s来同时选中两天序列。例如我们可以写出这样的SQL:
select s from root.sg.* where time > 1
那么以这条SQL为例,逻辑计划中记录的序列路径就是root.sg.*.s,那么在通过去星操作,生成的物理计划中记录的序列路径就是root.sg.d1.s和root.sg.d2.s。
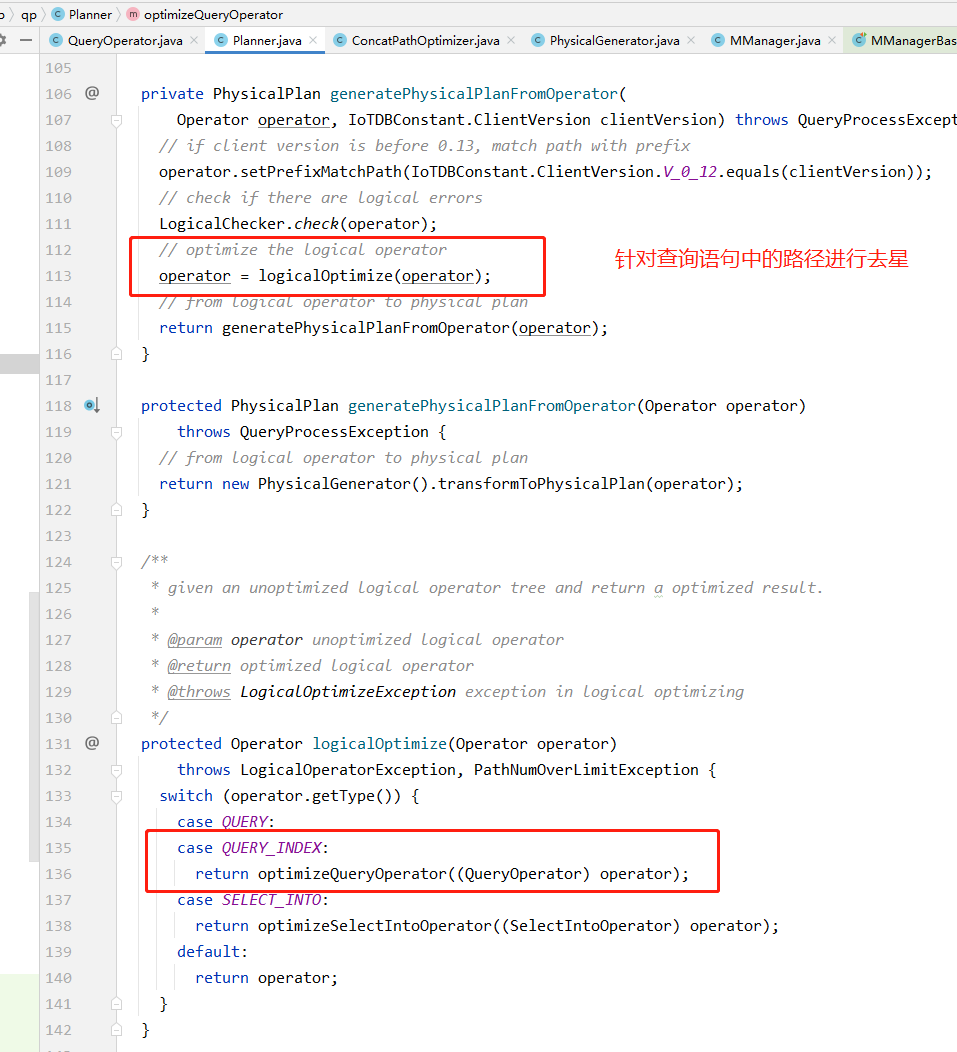
此外,IoTDB设计了PlanExecutor来实现服务层与底层存储引擎的解耦,服务层只负责请求的接受与计划的生成与调用执行,只需将物理计划传入PlanExecutor即可,无需关心底层存储引擎的实现。
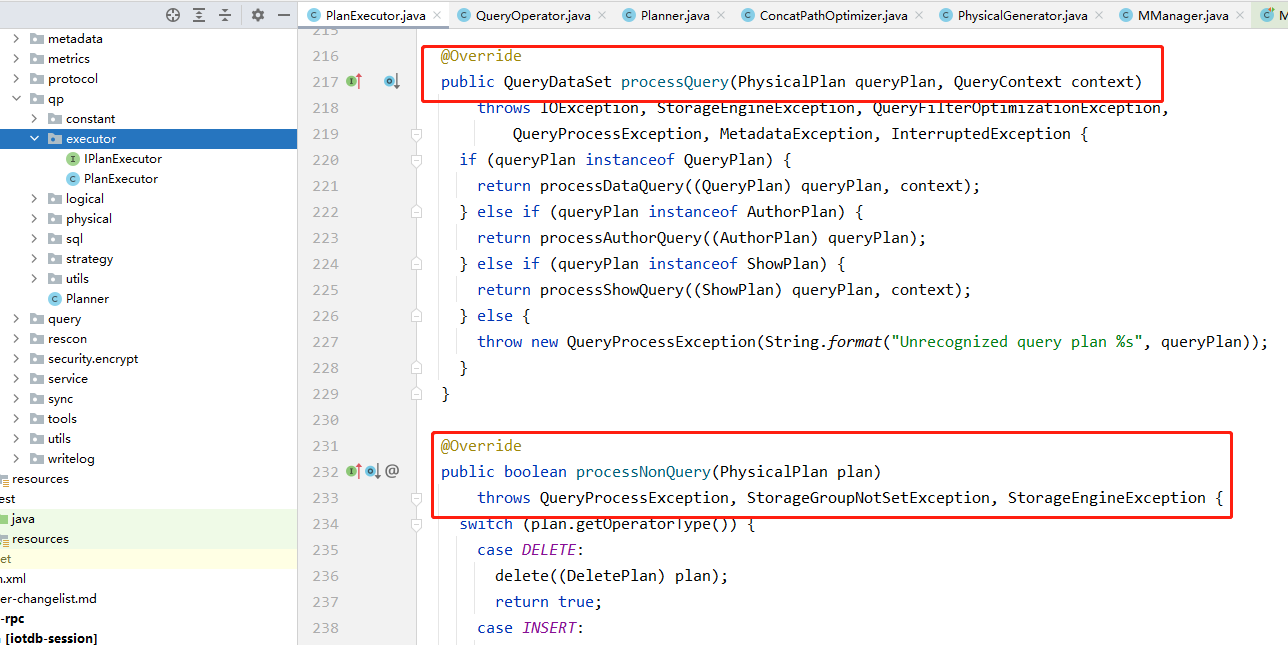
元数据树中的遍历查询任务
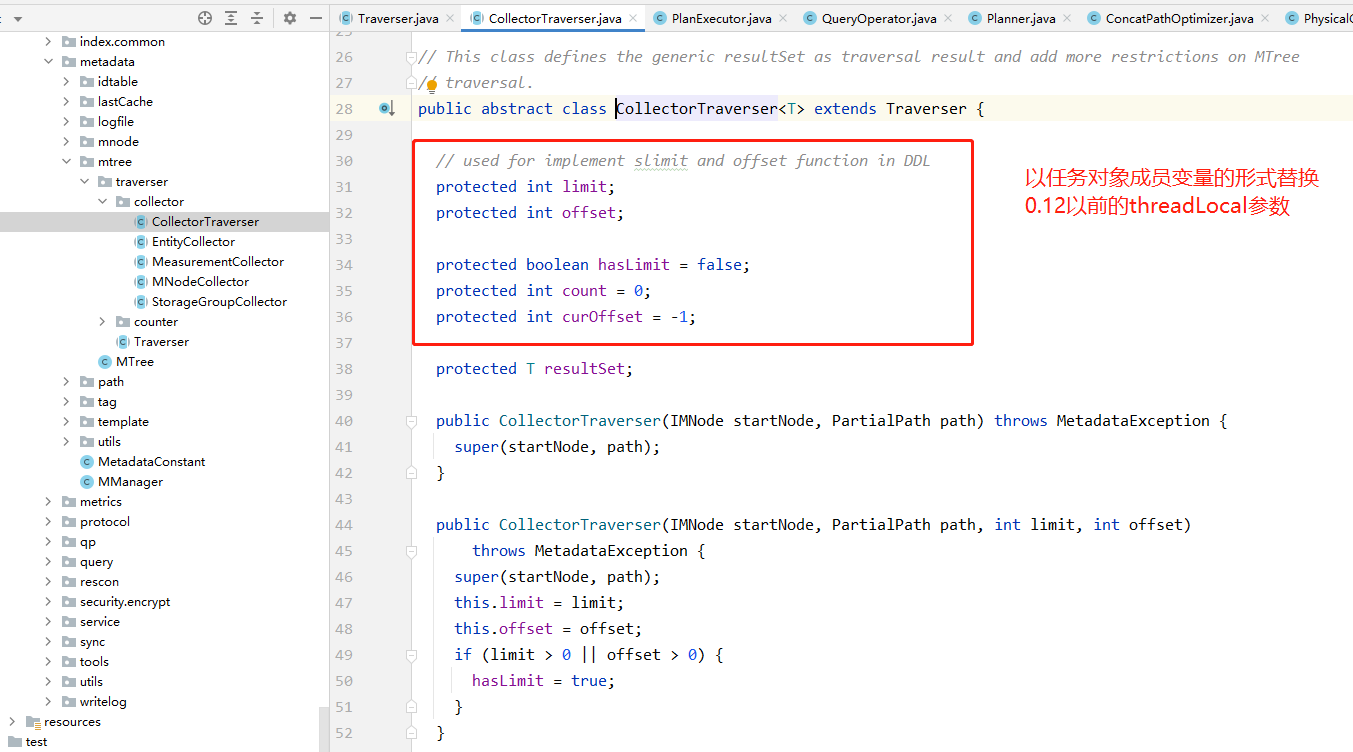
Apache IoTDB采用树形数据模型,实现上对应元数据模块,即/server/src/main/java/org/apache/iotdb/db/metadata包下的代码。IoTDB提供了丰富的针对元数据树操作的DDL,包括统计序列、查询匹配的序列等。以序列查询为例,该任务类似上文所说的去星操作,也是根据输入的逻辑路径来获取其对应的实际物理路径。同时该功能还支持limit、offset等操作。
在0.12及之前的MTree代码中,序列查询对应MTree.findPath方法,可以看到该方法是一个针对树的递归遍历操作,在递归过程中,递归函数的参数数量相当多,除了一开始的任务输入参数,还需要维护遍历过程中的一些状态信息以及结果集。
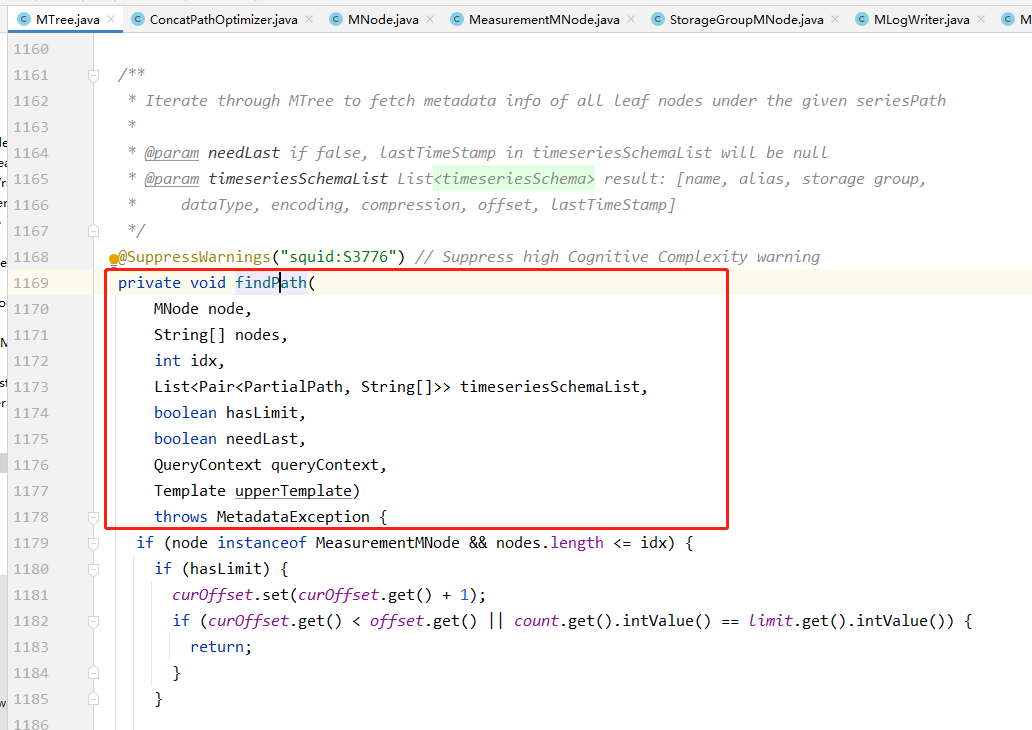
这里的实现也采用全局变量的方式来简化函数接口,但是上文我们分析过,全局变量的方式难以支撑多线程。于是为了解决这个问题,该版本的代码利用了Java中的ThreadLocal功能,将全局变量定义为ThreadLocal的,这样就解决了线程之间的相互影响。
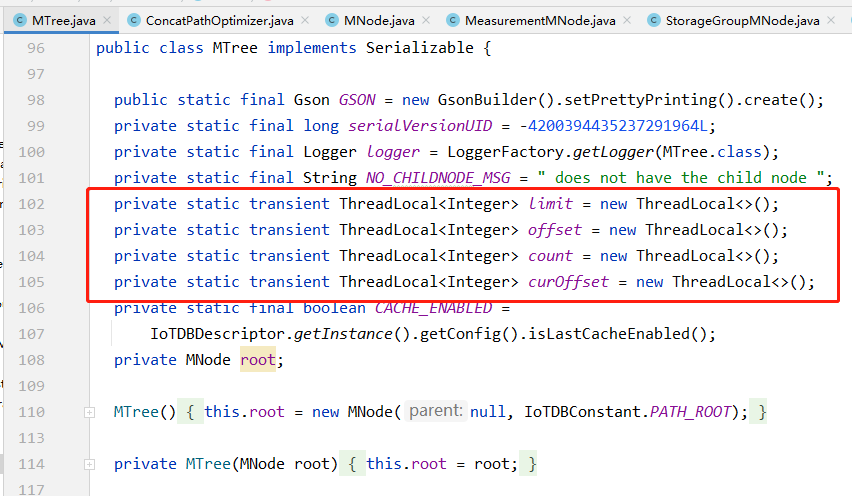
从0.13开始,IoTDB的MTree部分的代码经历了大的调整,引入了Traverser框架。针对每一种元数据树的查询任务,代码中定义了具体的Traverser类(部分简单的类采用匿名方式嵌入MTree代码中)。Traverser类的成员变量涵盖了该任务的输入参数以及树遍历过程中的状态信息,同时Traverser定义了树的遍历过程,封装在tarverse()方法中。不难看出,Traverser类完整定义了一个元数据查询任务,包括任务描述(输入)与任务执行过程(遍历方法与状态信息)。
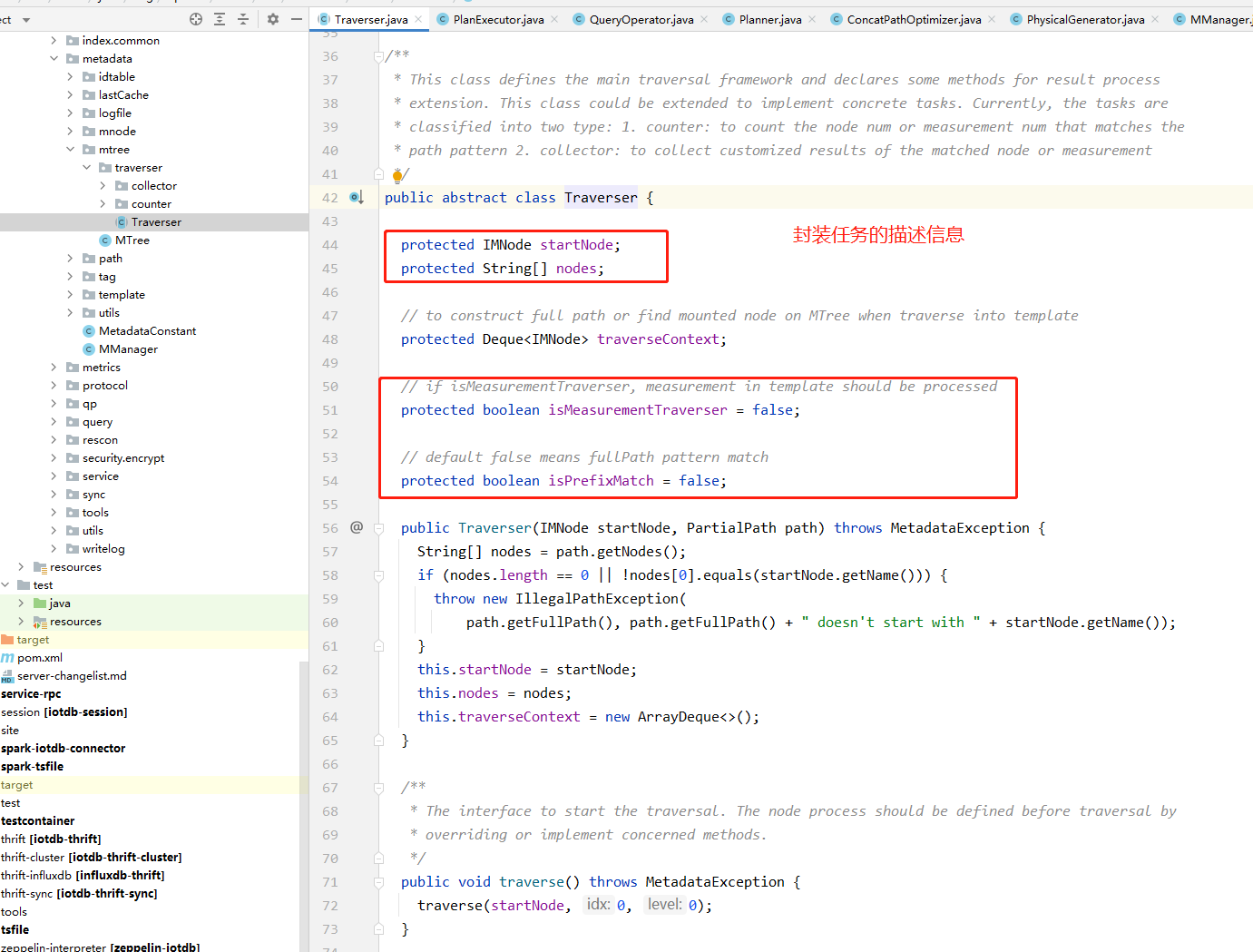
同时,Traverser通过成员变量的方式,取缔了0.12以前版本中所使用的ThreadLocal功能,一个Traverser对象对应一个查询任务,其成员变量之间天然隔离,不存在相互影响的问题。